M3L Architecture
Masked Multimodal Learning (M3L) is a representation learning technique for reinforcement learning that targets robotic manipulation systems provided with vision and high-resolution touch. Specifically, M3L learns a policy conditioned on multimodal representations, which are extracted from visual and tactile data through a shared representation encoder. As illustrated below, the M3L representations are trained by simultaneously optimizing both representation learning and reinforcement learning objectives.
Results



Example Rollouts
Tactile sensing at the two gripper fingers.
Generalization on two novel pegs.
Training Environment
Generalization Environment
Tactile sensing at the two gripper fingers.
Generalization on 10x higher friction and damping of the door, and on variations of its position.
Training Environment
Generalization Environment
Tactile sensing at the palm and all fingers.
Generalization on 2x object mass and altered camera pose.
Training Environment
Generalization Environment
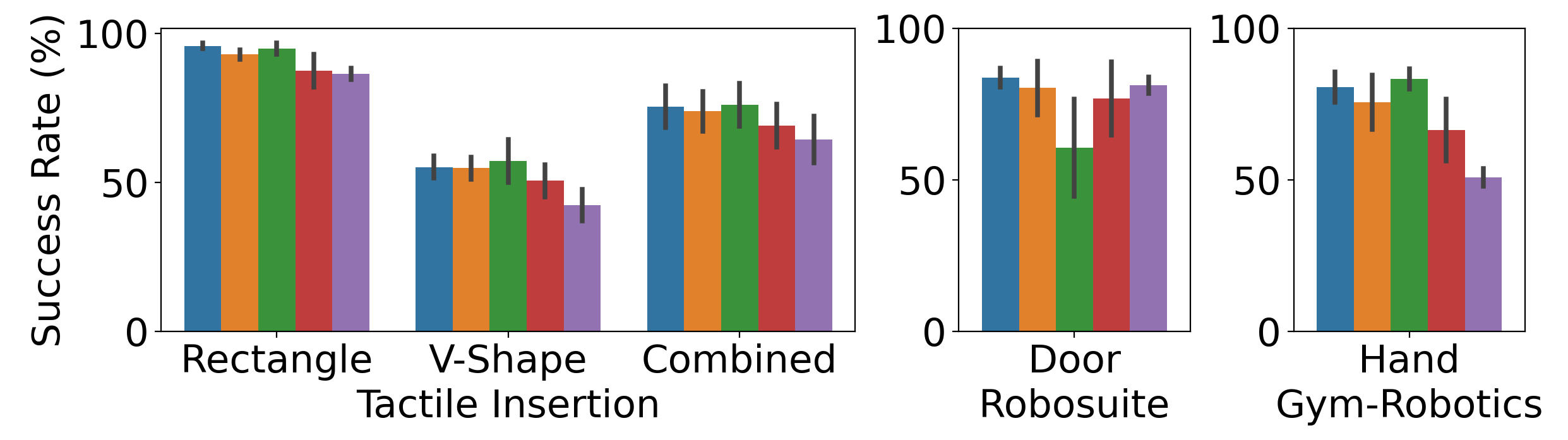
Generalization performance
To evaluate the capabilities unlocked by multimodality, in this work we considered scenarios where both modalities are informative during most of the training episodes, i.e., visual information is most of the times sufficient to learn the task. Such a setting is especially suitable to isolate the effect of the multimodal representations (compared, for example, to the use of a single modality). In particular, we investigate the generalization capabilities unlocked by the multimodal representations when dealing with unseen objects or conditions.
For the tactile insertion, we pretrain a policy on a set of 18 training objects, and test the zero-shot generalization on two different objects, which are a rectangular prism and V-shaped object. Such objects are not seen during training, and the V-shaped object considerably differs from the training objects. For the door opening task, we randomize the initial position of the door, as well as the friction and damping coefficients of the hinges. All of these parameters were instead fixed during training. Finally, for the in-hand rotation, we double the mass of the cube and slightly perturb the camera pose.

Baselines
- M3L: our approach jointly learns visual-tactile representations using a multimodal MAE and the policy using PPO.
- M3L (vision policy): while representations are trained from both visual and tactile data, the policy takes only visual data, exploiting the variable input length of the ViT encoder.
- Sequential: an M3L architecture trained independently for the different modalities in sequence. At each MAE training iteration, we first propagate the gradient for vision and then for touch. In this way, visual features cannot attend tactile features and vice versa.
- Vision-only (w/ MAE): an MAE approach with the same architecture as M3L, but trained only from visual inputs.
- End-to-end: a baseline that trains the policy end-to-end but with the same encoder architecture as M3L.
Takeaways
M3L consistently competes with or outperforms the end-to-end baseline and all the other representation learning approaches on all tasks. In particular, M3L substantially outperforms the vision-only approach, exploiting the power of multimodal representations. While the sequential baselines is competitive with M3L on the tactile insertion and in-hand reorientation tasks, it performs considerably worse on the door opening task. In particular, sequential training largely degrades due to observed training instabilities, indicating that attention across modalities enables the extraction of stronger and more general representations.
Interestingly, we observe a considerable improvement of M3L with vision policy over the vision-only baseline. They key insight is that using touch only for training the representation encoder is sufficient to substantially fill the gap with M3L on all tasks. This opens several remarkable opportunities, namely, I) a limited loss of generalization performance when touch is used at training time, but removed at deployment time, II) the possibility of training multimodal representations exclusively in simulation, and transferring a stronger vision policy to the real-world, wherever visual sim-to-real transfer is achievable \citep{james2019sim}.
BibTeX
@misc{sferrazza2023power,
title={The Power of the Senses: Generalizable Manipulation from Vision and Touch through Masked Multimodal Learning},
author={Carmelo Sferrazza and Younggyo Seo and Hao Liu and Youngwoon Lee and Pieter Abbeel},
year={2023},
eprint={2311.00924},
archivePrefix={arXiv},
primaryClass={cs.RO}
}